ReST is beautifully elegant. Consider this request to get all the products for a customer with id A1C908CE-170C-4479:
GET https://api.company.com/customer/A1C908CE-170C-4479/products
The beauty of it is that all variables in the request (in this case the customer id) can be cached as the URI is static, even though the data is dynamic. The implementation details of the business-logic are hidden and there is no tight coupling between the data request and the implementation.
Scalability == Flexability
Maybe the endpoint /products is handled by a completely different server then the endpoint /account. You could have a certain endpoint transparently connect to a third party, you could even spread ranges of customers over different servers:
/products -> server 10
/account -> server 8
/invoices -> api.3rdparty.com/yourID/customer/A1C9(...)9/invoices
ID range 00000001 - 30000000 -> server 1
ID range 30000001 - 60000000 -> server 2
...
Using ReST makes your application ready for the future, the possibilities are endless, and they can grow over time. For instance invoicing can be done by a third-party at first and then transfered in-house (or the other way around). The connections from the front-ends to the platform do not change, only the implementation changes.
Versionable
Consider you are in the process of upgrading the backend-code, maybe for the whole API or just one component, and you have at least one big user that is version-locked to the API.
In this scenario there are a few possibilities to mitigate that issue:
- version the whole api: https://api.company.com/v2.0/...
- version parts of the api: https://api.company.com/customer/v2.0/...
- send a http-header with the version you need: X-API-Version: 2.0
And then, if transparency is an issue, have the IP-Range for that client redirect to a different API version.
So with the ease of versioning, you can already implement the new version Alongside the current version, which is great for beta-testing. And again, you could redirect the new or beta version to completely different backend servers.
Implementation Abstraction
In older approaches to querying data as opposed to the ReSTfull way, it would translate to something like:
/customer.php?id=A1C908CE-170C-4479&query=account
Or /customer_account.php?customer_id=A1C908CE-170C-4479
Or /api.php?customer_id=A1C908CE-170C-4479&query=account
From the Example above, it should be clear that everything is so tighty coupled with the structure of the backend-logic that caching and scalability is a real and big issue.
An other advantage as demonstrated above is that ReST doen't leak implementation details. It could very well be that the code that retrieves the data, actually calls the more archaic scripts as shown above, but there is no tight coupling with the backend implementation. This is amazing when considering upgrading the backend software, implementing caching layers, scaling and even have different applications (even redirected to third partys) handle different endpoints of the API.
Go ReST!
In short: we believe that the only way to go is ReST, even if it is just the customer database accessed by an intranet page and the database server is located in the broom-closet, second door on the left. You never know what the future entails... With a ReST based application, you are ready for everything.
Send us an e-mail to inquire how we can help you design a scalable and robust platform.

 OTPManager is a One Time Password Manager and Authenticator where you can store and manage your One Time Passwords for Two Factor Authentication (2FA).
OTPManager is a One Time Password Manager and Authenticator where you can store and manage your One Time Passwords for Two Factor Authentication (2FA).

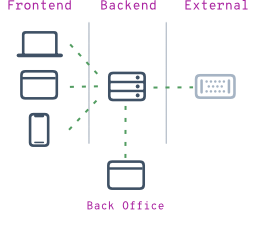

 We craft each and every app carefully, with a minimal everything approach, pouring in our love for minimalistic code and design. Combined with our modular mindset designing the
We craft each and every app carefully, with a minimal everything approach, pouring in our love for minimalistic code and design. Combined with our modular mindset designing the  We believe that inter-connectivity between devices is key in offering a satisfying customer experience. Back that up with a
We believe that inter-connectivity between devices is key in offering a satisfying customer experience. Back that up with a  We celebrate years of OTPManager
We celebrate years of OTPManager
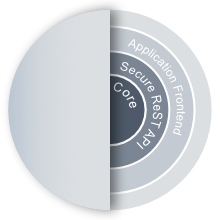 All our projects start with defining the
All our projects start with defining the 
 The big advantage is that is runs client-side (in the browser), so there is no strain on the servers when rendering the application. Javascript and more importantly the introduction of
The big advantage is that is runs client-side (in the browser), so there is no strain on the servers when rendering the application. Javascript and more importantly the introduction of  With all that awesomeness we now have native-browser-applications that can feel as solid as
With all that awesomeness we now have native-browser-applications that can feel as solid as 